您的网站检测是否运行不正常?
根据您网站的配置和结构,可能有多种原因导致某些页面被网站检测爬虫阻止,包括:
- Robots.txt 阻止爬虫
- 抓取范围不包括网站的某些区域
- 由于共享主机,网站未直接在线
- 着陆页大小超过 2Mb
- 页面位于网关之后 / 登录
- 爬虫被 noindex 标签阻止
- 域名无法通过 DNS 解析——设置中输入的域名处于离线状态
- 以 JavaScript 构建的网站内容——尽管网站检测可以渲染 JS 代码,但仍可能是某些问题的原因
故障排除步骤
遵循这些故障排除步骤,看看能否自行解决,若无法解决再联系支持团队寻求帮助。
Robots.txt 文件向爬虫提供了关于如何抓取(或如何不抓取)网站页面的指令。 您可以使用 Allow、Disallow 和 Crawl Delay 等命令来允许和禁止爬虫(例如 Googlebot 或 Semrushbot)抓取您网站的所有内容或特定区域。
如果您的 robots.txt 阻止了我们的机器人抓取您的网站,我们的网站检测工具将无法检查您的网站。
您可以检查 Robots.txt 文件中是否有阻止我们爬虫访问您网站的禁止命令。
要允许 Semrush 网站检测机器人(SiteAuditBot)抓取您的网站,请在 robots.txt 文件中添加以下内容:
User-agent: SiteAuditBot
Disallow:
(在“Disallow:”后留一个空格)
以下是 robots.txt 文件的示例:

请注意,文件针对不同的用户代理(爬虫)设置了各类指令。
这些文件是公开的,必须托管在网站的顶级目录中才能找到。 要找到网站的 robots.txt 文件,请在浏览器中输入网站的根域名,并在其后加上 /robots.txt。 例如,Semrush.com 上的 robots.txt 文件位于 https://semrush.com/robots.txt。
您在 robots.txt 文件中可能会看到以下一些术语:
- User-Agent = 您正在给出指令的网络爬虫。
- 例如:SiteAuditBot、Googlebot
- Allow =(仅限 Googlebot)告诉爬虫即使父页面或文件夹被禁止抓取也可抓取网站特定页面或区域的命令。
- Disallow = 告诉爬虫不要抓取网站特定 URL 或子文件夹的命令。
- 例如:Disallow: /admin/
- Crawl Delay = 告诉爬虫需要等待多少秒才能再加载和抓取另一页面的命令。
- Sitemap = 指示特定 URL 的 sitemap.xml 文件的位置。
- / = 在禁止命令后使用“/”符号,以指示爬虫不抓取您网站的所有内容
- * = 一个通配符符号,表示 URL 中任何可能字符的字符串,用于指示网站区域或所有用户代理。
- 例如:Disallow: /blog/* 表示网站博客子文件夹中的所有 URL
- 例如:User-agent: * 表示对所有爬虫的指令
从谷歌或 Semrush 博客阅读有关 Robots.txt 规范的更多信息。
如果您在网站的主页上看到以下代码,这表明我们无法索引/跟踪该页面的链接,并且我们的访问已被阻止。
meta name="robots" content="noindex, nofollow"
或包含以下至少一条内容的页面:“noindex”、“nofollow”、“none”,将导致抓取错误。
要允许我们的爬虫抓取这样的页面,请从页面的代码中移除这些“noindex”标签。 有关 noindex 标签的更多信息,请参阅这篇谷歌支持文章。
要将该机器人列入白名单,请联系您的网站管理员或主机提供商,并要求他们将 SiteAuditBot 列入白名单。
机器人的 IP 地址是:85.208.98.128/25(仅用于网站检测的子网)
该机器人使用标准的 80 HTTP 和 443 HTTPS 端口进行连接。
如果您使用任何插件(例如 Wordpress)或 CDN(内容分发网络)来管理您的网站,您还必须在这些服务中将该机器人 IP 列入白名单。
要在 Wordpress 中列入白名单,请联系 Wordpress 支持。
阻止我们爬虫的常见 CDN 包括:
- Cloudflare - 点击此处阅读如何列入白名单
- Imperva - 点击此处阅读如何列入白名单
- ModSecurity - 点击此处阅读如何列入白名单
- Sucuri - 点击此处阅读如何列入白名单
请注意:如果您使用的是共享主机服务,那么您的主机提供商可能不允许您将任何机器人程序列入白名单,也不允许您编辑 Robots.txt 文件。
主机提供商
以下是一些最热门主机提供商的列表,以及如何在每个提供商上将爬虫列入白名单或联系其支持团队寻求帮助:
- Siteground - 列入白名单的说明
- 1&1 IONOS - 列入白名单的说明
- Bluehost* - 列入白名单的说明
- Hostgator* - 列入白名单的说明
- Hostinger - 列入白名单的说明
- GoDaddy - 列入白名单的说明
- GreenGeeks - 列入白名单的说明
- Big Commerce - 必须联系支持
- Liquid Web - 必须联系支持
- iPage - 必须联系支持
- InMotion - 必须联系支持
- Glowhost - 必须联系支持
- Hosting - 必须联系支持
- DreamHost - 必须联系支持
* 请注意:如果您的网站托管在 VPS 或专用主机上,这些指令适用于 HostGator 和 Bluehost。
如果您的着陆页面大小或 JavaScript/CSS 文件的总大小超过 2Mb,由于工具的技术限制,我们的爬虫将无法处理。
要了解可能导致大小增加的原因以及如何解决此问题,您可以参考我们博客中的这篇文章。
要查看您当前的抓取预算已使用多少,请访问资料—订阅信息,并在“SEO 工具箱”下查找“可抓取的页面”。
根据您的订阅级别,您每月可抓取的页面数量是有限制的(每月抓取预算)。 如果您超出了订阅中允许的页面数量,您需要购买额外的限额或等待下个月限额刷新。
此外,如果您在设置过程中遇到错误信息“您已达到同时运行的营销活动的限额”,这意味着您已达到您的订阅级别允许同时运行网站检测的最大数量。
每个订阅级别包含不同的限额:
- 免费账户:一次只能运行 1 次网站审核
- 专业 SEO 工具箱:最多可以同时进行 2 次网站检测
- Guru SEO 工具箱:最多可以同时运行 2 次网站检测
- Business SEO 工具箱:最多可以同时运行 5 次网站检测
如果域名无法通过 DNS 解析,这可能说明您在配置中输入的域名处于离线状态。 通常,用户在输入根域名 (example.com) 时会遇到此问题,因为他们未意识到其网站的根域名版本并不存在,而需要输入的是其网站的 WWW 版本 (www.example.com)。
为避免此问题,网站所有者可在服务器上添加一条重定向规则,将未加密的“example.com”重定向至已加密的“www.example.com”。 如果根域名可访问但 WWW 版本不可访问,也可能出现相反的情况。 在这种情况下,您只需将 WWW 版本重定向到根域名即可。
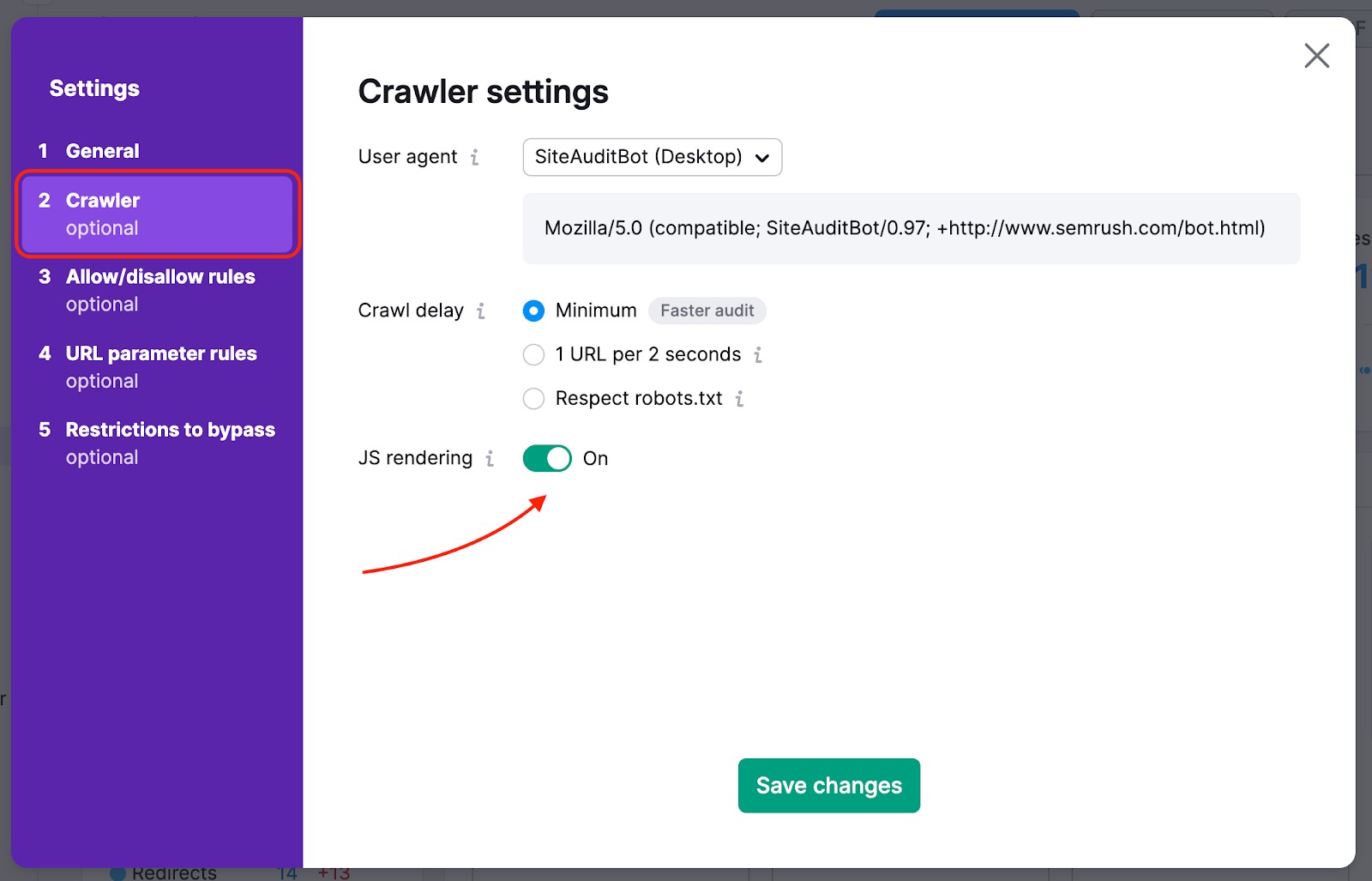
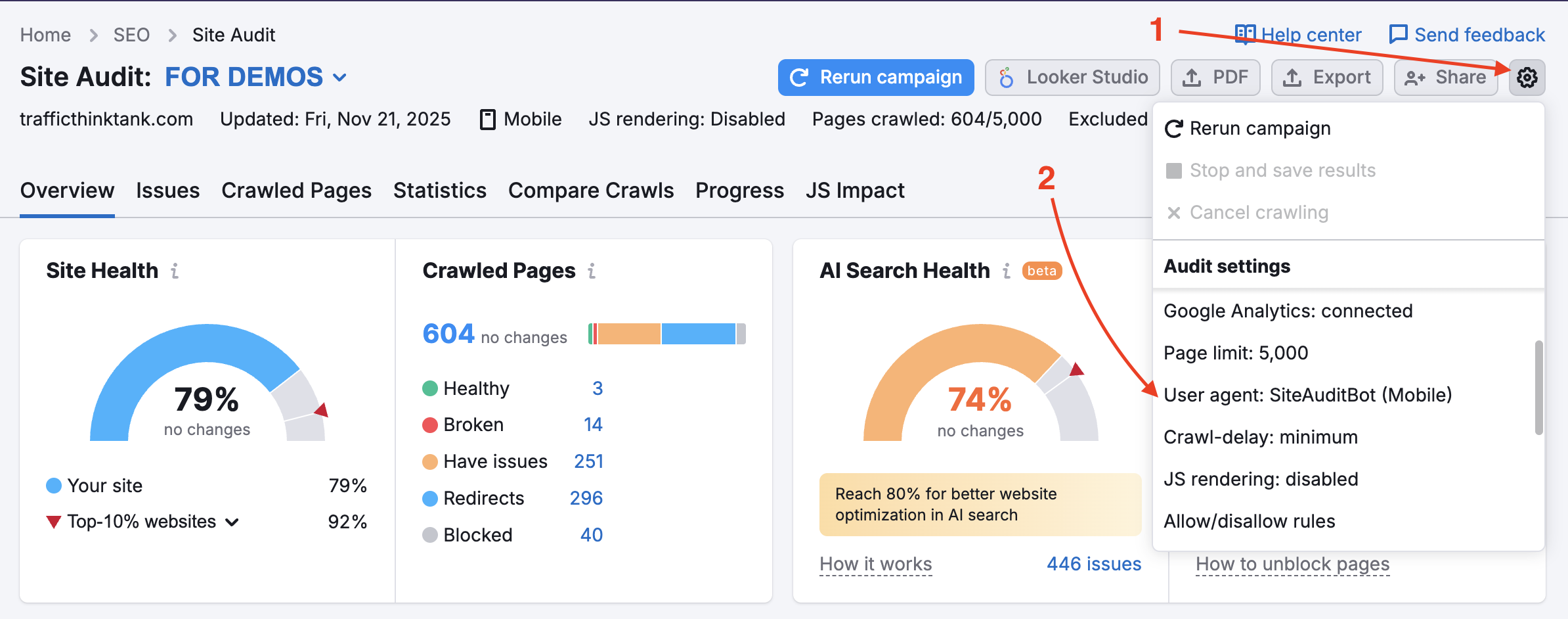
您的网站可能在 robots.txt 文件中阻止了 SemrushBot。 您可以将用户代理从 SemrushBot 更改为 GoogleBot,这样您的网站可能会允许谷歌的用户代理抓取。 要进行此更改,请在项目中找到设置齿轮并选择“用户代理”。
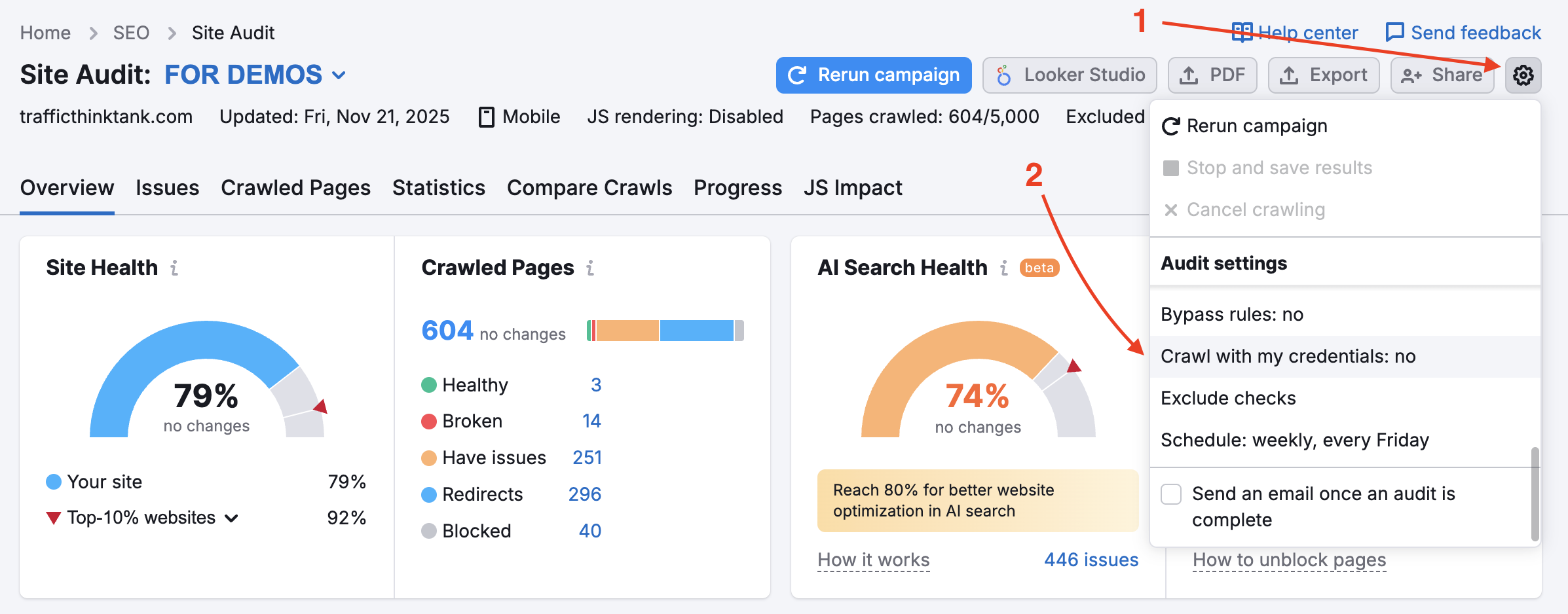
启用此选项后,抓取器将绕过 robots.txt 的禁止 (disallow) 规则,因此通常会被屏蔽的页面和内部资源仍会被抓取。 请注意,使用此功能需要验证网站所有权。
这对于当前处于维护中的网站非常有用。 当网站所有者不想修改 robots.txt 文件时,使用此功能也很有帮助。
要检测网站上受密码保护的私有区域,请在设置齿轮下的“使用凭证抓取”选项中输入您的凭证。
对于仍在开发的网站或完全受密码保护的私有网站,强烈建议使用此选项。
出于安全或性能原因,某些网站和托管平台(如 Shopify)可能会默认阻止未知爬虫。 如果您在这些平台上的检测失败,添加 Web Bot Auth 签名可让 Semrush 爬虫表明身份,并证明其已获授权访问您的网站。

如果您在初始设置时未提供签名且您的网站被屏蔽,Semrush 会检测到该限制,并提示您在工具界面中直接修复。

“您的爬虫设置自上一次检测以来已更改。 这可能会影响您当前的检测结果和检测到的问题数量。”
在您更新任何设置并重新运行检测后,此通知将显示在网站检测中。 这并非表示存在问题,而是说明如果抓取结果意外变化,这可能是原因所在。
查看我们的博客文章常见 SEO 问题及其解决方案。